Running a retrospective analysis on a FIMS model
retrospective.RmdSet up FIMS model
Following the minimal FIMS demo vignette, we will set up a FIMS model and run it. This model will contain the all years of data and will be our reference model (see section below for more information about reference models). For this example we are using the dataset included in the FIMS package and creating a set of default parameters.
# Load sample data
data("data_big")
# Prepare data for FIMS model
data_4_model <- FIMSFrame(data_big)
# Create parameters
parameters <- data_4_model |>
create_default_configurations() |>
create_default_parameters(data = data_4_model)
# Run the model with optimization
base_model <- parameters |>
initialize_fims(data = data_4_model) |>
fit_fims(optimize = TRUE)
#> ✔ Starting optimization ...
#> ℹ Restarting optimizer 3 times to improve gradient.
#> ℹ Maximum gradient went from 0.005 to 0.00038 after 3 steps.
#> ✔ Finished optimization
#> ✔ Finished sdreport
#> ℹ FIMS model version: 0.9.2
#> ℹ Total run time was 35.28465 seconds
#> ℹ Number of parameters: fixed_effects=49, random_effects=29, and total=78
#> ℹ Maximum gradient= 0.00038
#> ℹ Negative log likelihood (NLL):
#> • Marginal NLL= 3231.28735
#> • Total NLL= 3164.86339
#> ℹ Terminal SB= 1728.69146
# Clear memory post-run
clear()Retrospective analysis
A retrospective analysis is a common model diagnostic used to assess how stable model estimates such as spawning biomass and fishing mortality are and if there is a consistent pattern in the estimates as years of data are removed. The process involves removing n years of data from the end of the time series and refitting the model. This is an iterative process where the user typically runs 5-10 models, with each run (often called “peels”) progressively removing another year of data. Derived quantities such as spawning biomass, fishing mortality (F), and recruitment over the years of included data are compared to the model run with the full dataset (reference model). The Mohn’s rho statistic can be used to compare the relative difference between the reference model and each peel. Mohn’s rho statistic is calculated as:
where is the number of retrospective peels, is the estimated value (e.g. spawning biomass, fishing mortality, etc.) from peel at its terminal year , and is the value from the reference model, , at that same year .
Some things to note about the run_fims_retrospective()
function, you can provide data that is already a FIMSFrame
object or you can give it one that is not. In the example below, we are
using the FIMSFrame data object (data_4_model)
created above. Additionally, it expects a vector of positive values of
years_to_remove from the base model, starting from 0. If
you are running many peels, it may be more efficient to use multiple
cores, which can be specified by the n_cores argument.
NOTE: If left empty, the default for
n_coresis one less than the number of cores on your machine so this could unexpectedly use up a lot of your computing power.
retro_fit <- run_fims_retrospective(years_to_remove = 0:2,
data_4_model, parameters,
n_cores = 1)
#> ℹ ...Running sequentially on a single core
#> ℹ running model with 0 years of data removed
#> ✔ Starting optimization ...
#> ℹ Restarting optimizer 3 times to improve gradient.
#> ℹ Maximum gradient went from 0.005 to 0.00038 after 3 steps.
#> ✔ Finished optimization
#> ✔ Finished sdreport
#> ℹ FIMS model version: 0.9.2
#> ℹ Total run time was 34.98599 seconds
#> ℹ Number of parameters: fixed_effects=49, random_effects=29, and total=78
#> ℹ Maximum gradient= 0.00038
#> ℹ Negative log likelihood (NLL):
#> • Marginal NLL= 3231.28735
#> • Total NLL= 3164.86339
#> ℹ Terminal SB= 1728.69146
#> ℹ running model with 1 years of data removed
#>
#> ✔ Starting optimization ...
#> ℹ Restarting optimizer 3 times to improve gradient.
#> ℹ Maximum gradient went from 0.00564 to 6e-04 after 3 steps.
#> ✔ Finished optimization
#> ✔ Finished sdreport
#> ℹ FIMS model version: 0.9.2
#> ℹ Total run time was 39.04599 seconds
#> ℹ Number of parameters: fixed_effects=49, random_effects=29, and total=78
#> ℹ Maximum gradient= 6e-04
#> ℹ Negative log likelihood (NLL):
#> • Marginal NLL= 3132.00827
#> • Total NLL= 3066.98892
#> ℹ Terminal SB= 1654.15659
#> ℹ running model with 2 years of data removed
#>
#> ✔ Starting optimization ...
#> ℹ Restarting optimizer 3 times to improve gradient.
#> ℹ Maximum gradient went from 0.00597 to 0.00035 after 3 steps.
#> ✔ Finished optimization
#> ✔ Finished sdreport
#> ℹ FIMS model version: 0.9.2
#> ℹ Total run time was 34.32031 seconds
#> ℹ Number of parameters: fixed_effects=49, random_effects=29, and total=78
#> ℹ Maximum gradient= 0.00035
#> ℹ Negative log likelihood (NLL):
#> • Marginal NLL= 3036.85438
#> • Total NLL= 2973.27387
#> ℹ Terminal SB= 1500.1442Mohn’s Rho
Once you have run a retrospective, you can then calculate the Mohn’s rho statistic for spawning biomass by:
rho_sb <- calculate_mohns_rho(retro_fit, quantity = "spawning_biomass")Visualize the results
To visualize the results of the retrospective analysis, we can use
plot_retrospective to display the quantity of interest.
Below, we want to assess the impact on spawning biomass. The function
returns a ggplot object so to customize the default figure,
you can add layers as you normally would to a ggplot. For
example, below, we specify the x and y axes labels and the legend
title.
🚧 Under development We are actively working on expanding which quantities can be visualized with the
plot_retrospectivefunction but for now, it is limited tospawning_biomass.
# plot the SSB time series from each model
fig_retrospective_ssb <- plot_retrospective(retro_fit) +
ggplot2::labs(x = "Year", y = "Spawning Biomass") +
ggplot2::guides(fill = ggplot2::guide_legend(title = "Retro Peel"),
color = ggplot2::guide_legend(title = "Retro Peel"),
linetype = ggplot2::guide_legend(title = "Retro Peel"))
#> Saving 9 x 7 in image
print(fig_retrospective_ssb)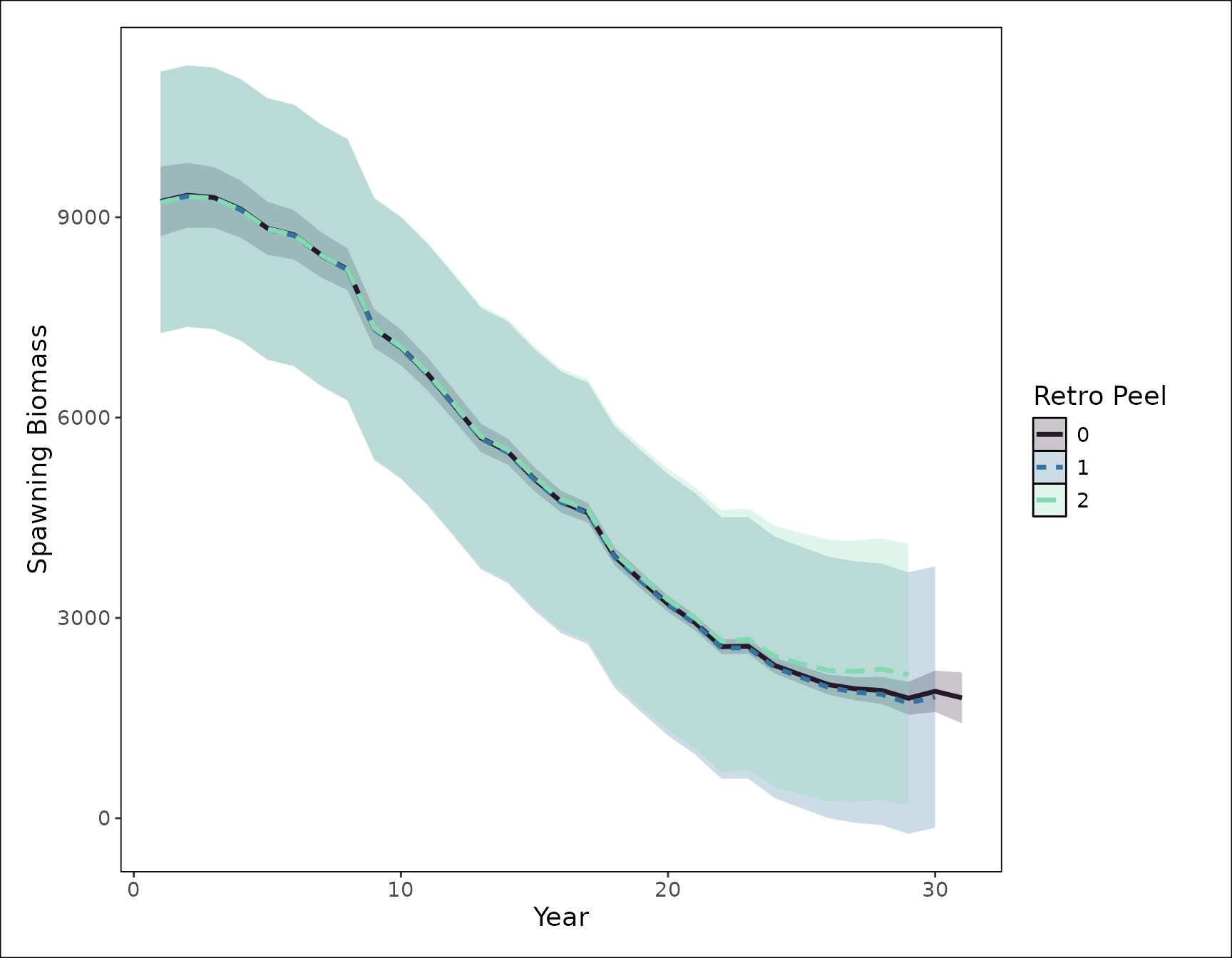
We can compare the spawning biomass estimates from the reference model and each peel for the last six years.
retro_fit[["estimates"]] |>
dplyr::filter(label == "spawning_biomass") |>
dplyr::select(label, year_i, estimated, retrospective_peel) |>
tidyr::pivot_wider(names_from = retrospective_peel, values_from = estimated) |>
dplyr::rename(
"Year" = year_i,
"Reference model" = `0`,
"Peel 1" = `1`,
"Peel 2" = `2`
) |>
tail()
#> # A tibble: 6 × 5
#> label Year `Reference model` `Peel 1` `Peel 2`
#> <chr> <int> <dbl> <dbl> <dbl>
#> 1 spawning_biomass 26 1979. 1916. 1947.
#> 2 spawning_biomass 27 1895. 1817. 1856.
#> 3 spawning_biomass 28 1849. 1754. 1801.
#> 4 spawning_biomass 29 1724. 1618. 1640.
#> 5 spawning_biomass 30 1827. 1727. 1678.
#> 6 spawning_biomass 31 1729. 1654. 1500.Clean up
Once you have finished running a FIMS model, it is always good practice to clear the C++ memory from one FIMS model run to the next.
clear()