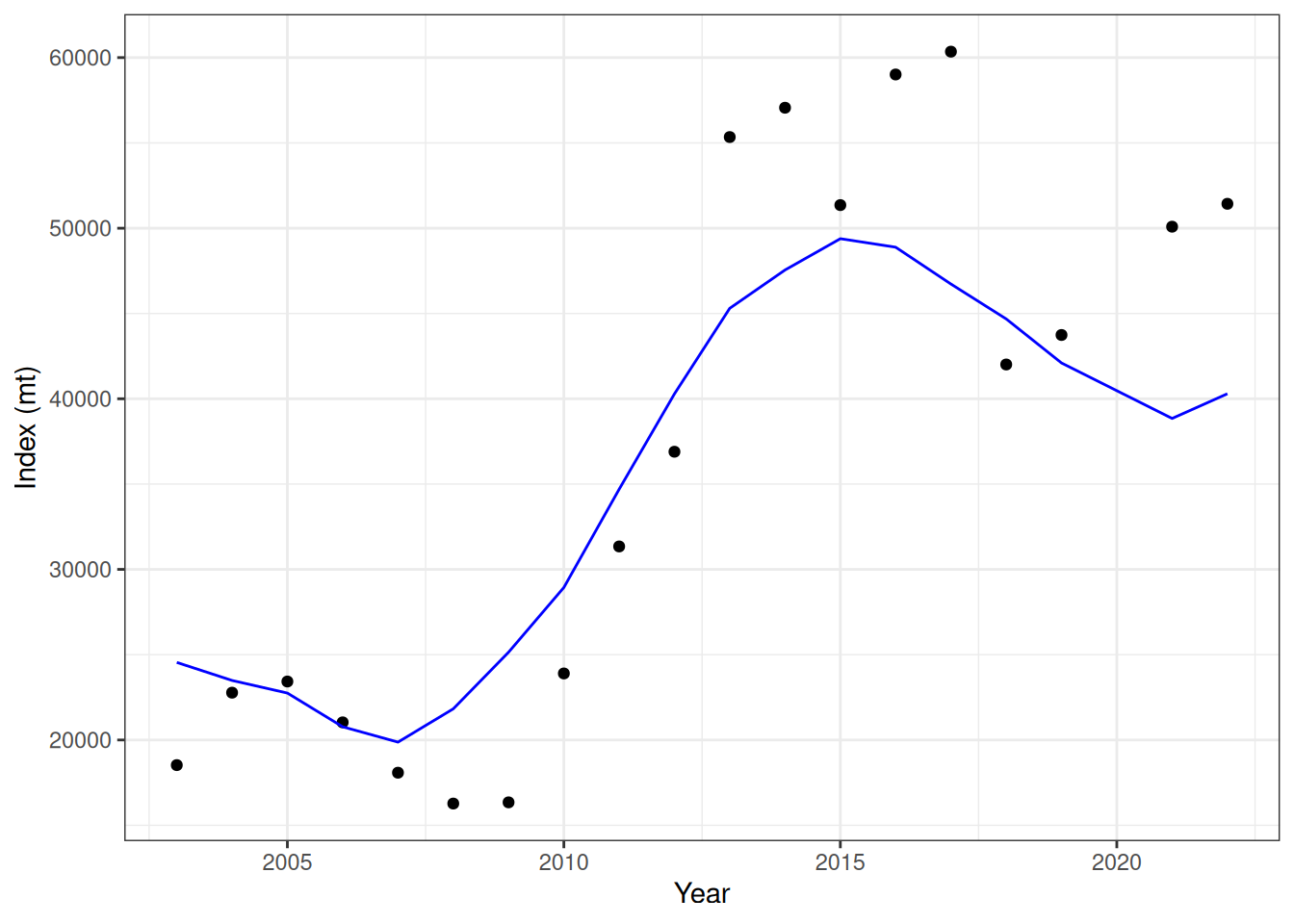
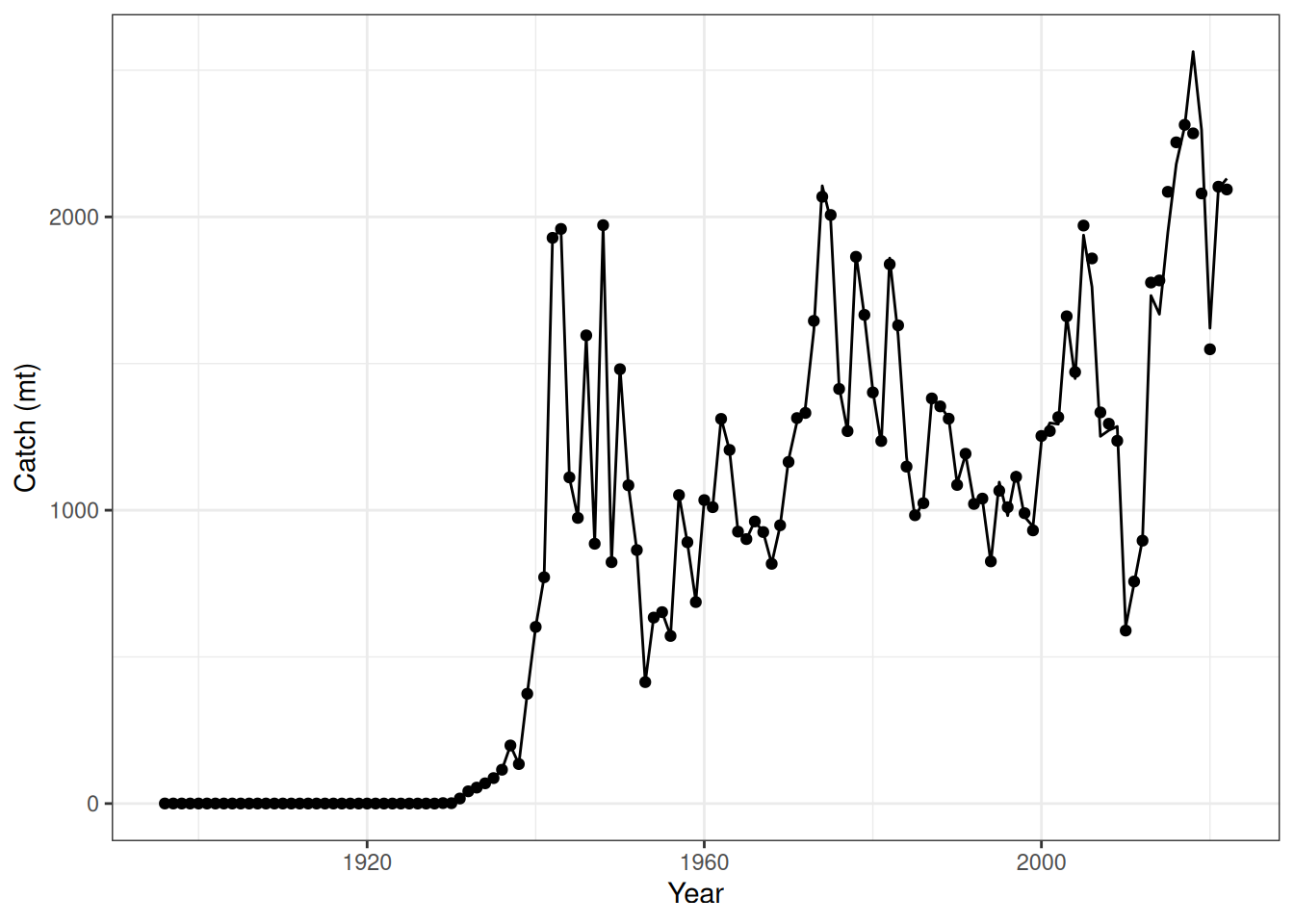
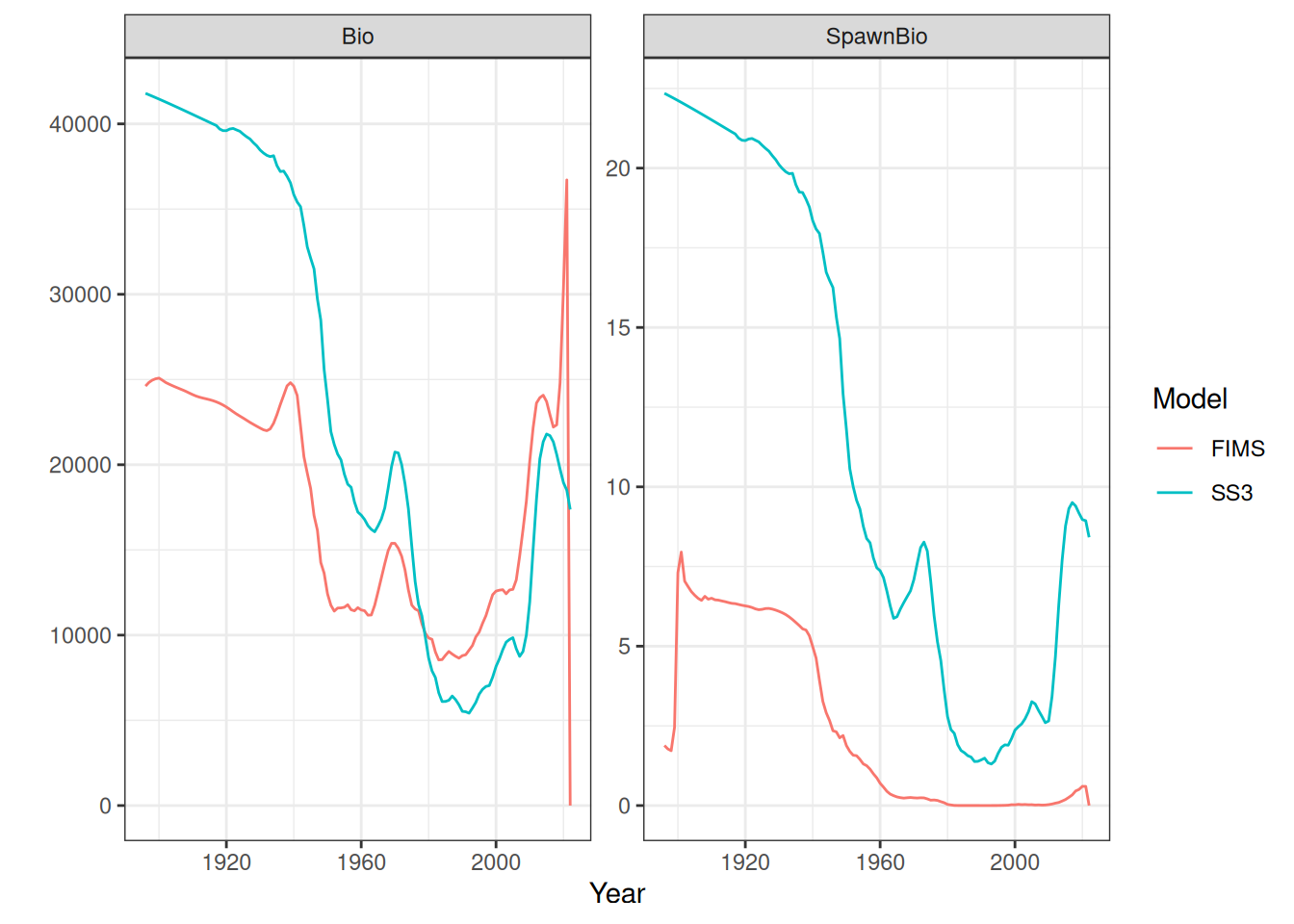
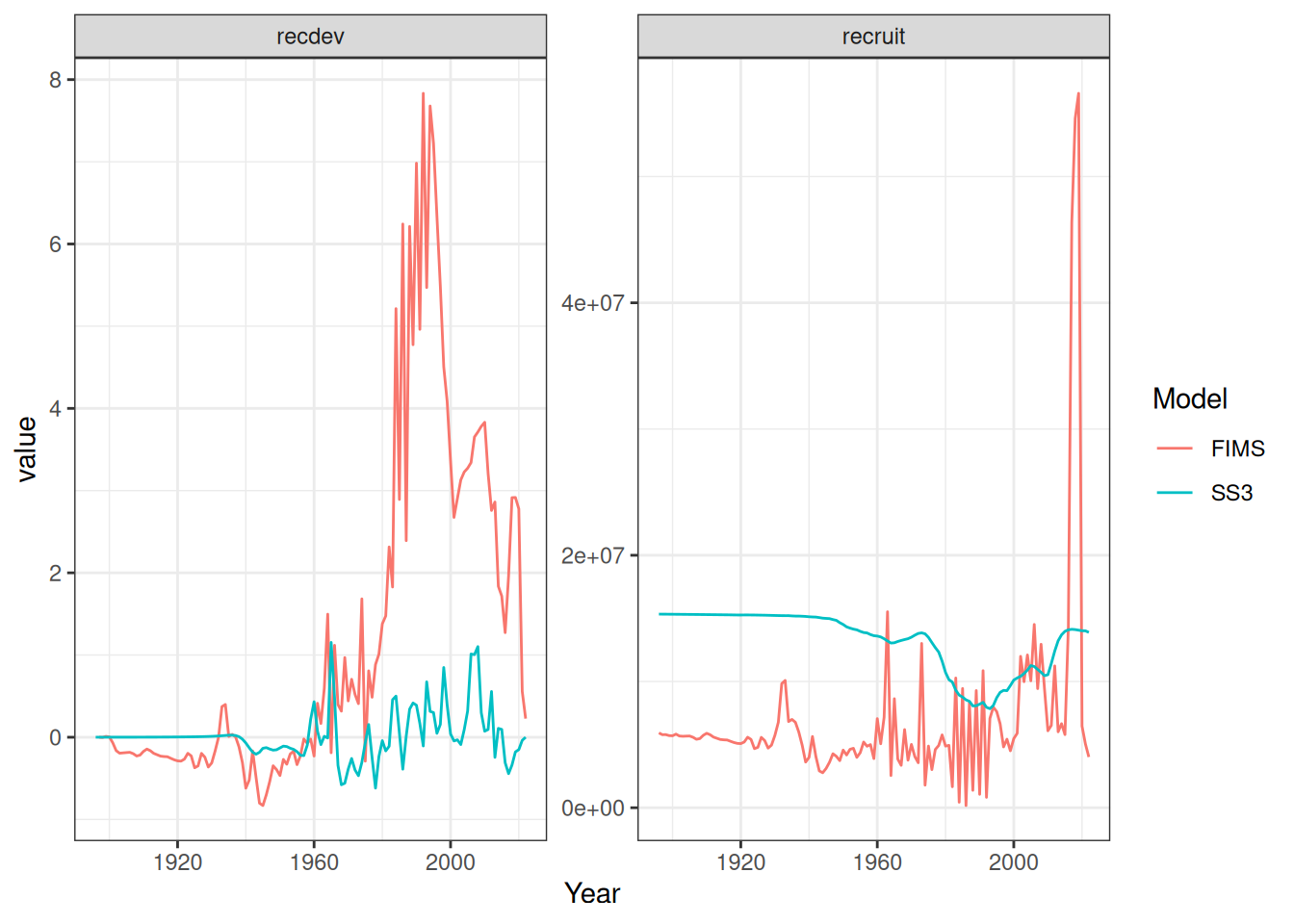
# lots of code below copied PIFSC-opakapaka.qmd
# rename SS3 output to avoid modifying lines copied from opakapaka model
rep <- petrale_output
# Create default parameters
default_parameters <- FIMS::create_default_configurations(
data = data_4_model
) |>
FIMS::create_default_parameters(
data = data_4_model
) |>
tidyr::unnest(cols = data)
recdevs <- rep$recruitpars |> # $recruitpars is a subset of $parameters with Yr as an additional column
dplyr::filter(Yr %in% years[-1]) |> # filter out initial numbers parameters
dplyr::select(Yr, Value)
init_naa <- rep$natage |>
dplyr::filter(Time == min(years), Sex == 1) |> # numbers at age in FIMS start year, not SS3 model
dplyr::select(paste(ages)) |>
as.numeric() # TODO: figure out if *1000 is needed
init_naa <- exp(rep$parameters |> dplyr::filter(grepl("R0", Label)) |> dplyr::pull(Init)) * 1000 * exp(-(ages - 1) * rep$parameters |> dplyr::filter(grepl("NatM.*Fem", Label)) |> dplyr::pull(Value))
init_naa[n_ages] <- init_naa[n_ages] / rep$parameters |> dplyr::filter(grepl("NatM.*Fem", Label)) |> dplyr::pull(Value) # sum of infinite series
parameters <- default_parameters |>
# SS3 model had length-based selectivity which leads to sex-specific
# age-based selectivity due to sexually-dimorphic growth.
# I didn't bother to calculate an age-based inflection point averaged over sexes
dplyr::rows_update(
tibble::tibble(
module_name = "Maturity",
label = c("inflection_point", "slope"),
value = c(20.5, 1.8), # arbitrary guess of slope
),
by = c("module_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Selectivity",
fleet_name = "fleet1",
label = c("inflection_point", "slope"),
value = c(10, 2),
estimation_type = "constant"
),
by = c("module_name", "fleet_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Selectivity",
fleet_name = "survey1",
label = c("inflection_point", "slope"),
value = c(6, 2),
estimation_type = "constant"
),
by = c("module_name", "fleet_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Recruitment",
label = c("log_rzero", "logit_steep", "log_sd"),
value = c(
petrale_input$ctl$SR_parms["SR_LN(R0)", "INIT"],
FIMS::logit(0.2, 1.0, petrale_input$ctl$SR_parms["SR_BH_steep", "INIT"]),
0.5
)
),
by = c("module_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Recruitment",
label = "log_devs",
time = (FIMS::get_start_year(data_4_model) + 1):FIMS::get_end_year(data_4_model),
# The last value of the initial numbers at age is the first
# recruitment deviation
value = recdevs$Value,
),
by = c("module_name", "label", "time")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Population",
label = "log_init_naa",
age = FIMS::get_ages(data_4_model),
value = log(init_naa),
estimation_type = "fixed_effects"
),
by = c("module_name", "label", "age")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Population",
label = "log_M",
value = log(rep$parameters["NatM_uniform_Fem_GP_1", "Value"]),
estimation_type = "constant"
),
by = c("module_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Fleet",
fleet_name = "fleet1",
time = years,
label = "log_Fmort",
estimation_type = "constant",
value = rep[["exploitation"]] |>
dplyr::filter(Yr %in% years) |>
dplyr::mutate(North = ifelse(North == 0, -999, log(North))) |>
dplyr::pull(North)
),
by = c("module_name", "fleet_name", "label", "time")
)
# Run the model without optimization to help ensure a viable model
test_fit <- parameters |>
FIMS::initialize_fims(data = data_4_model) |>
FIMS::fit_fims(optimize = FALSE)
# Run the model with optimization
fit <- parameters |>
FIMS::initialize_fims(data = data_4_model) |>
FIMS::fit_fims(optimize = TRUE, get_sd = FALSE)