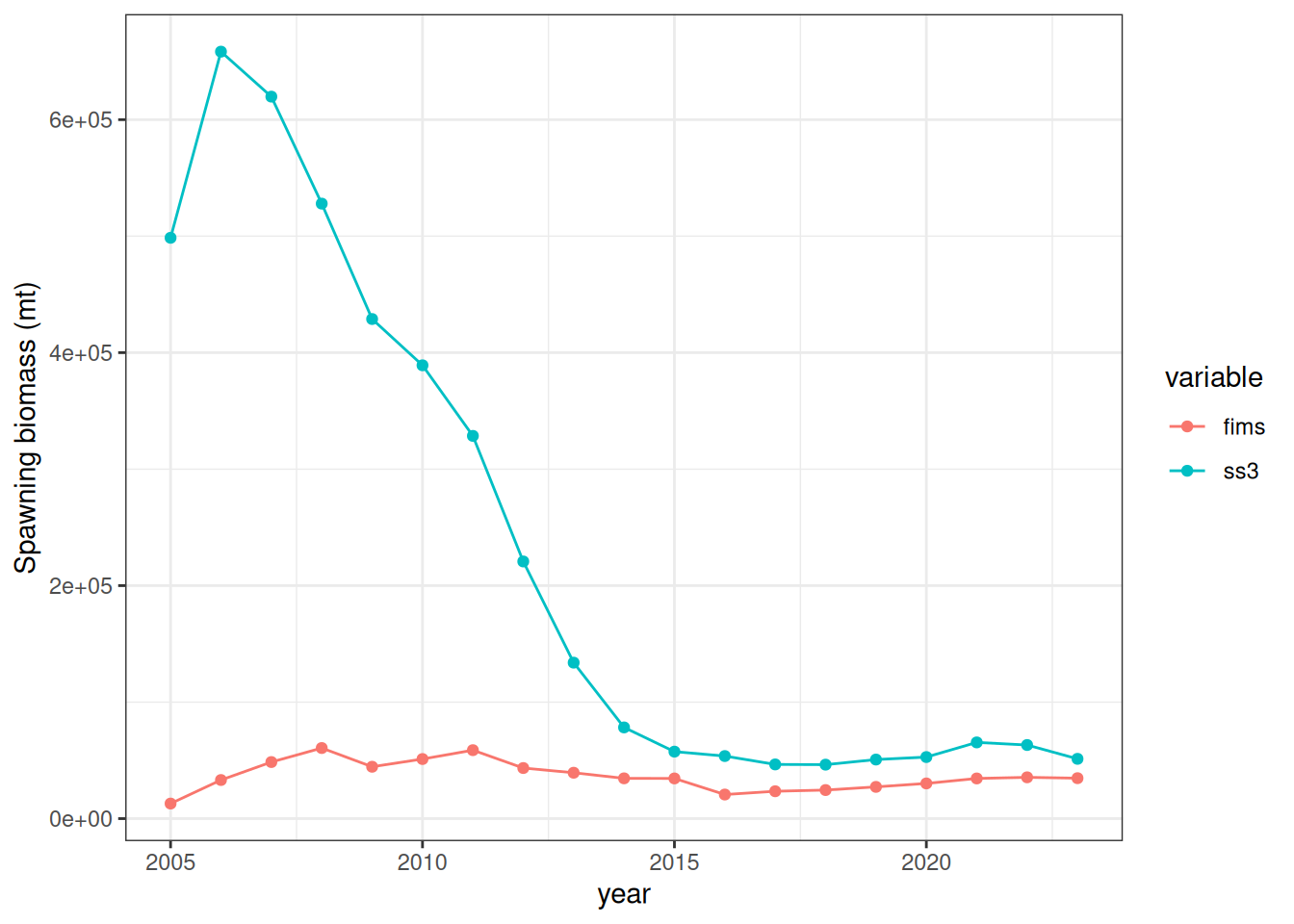
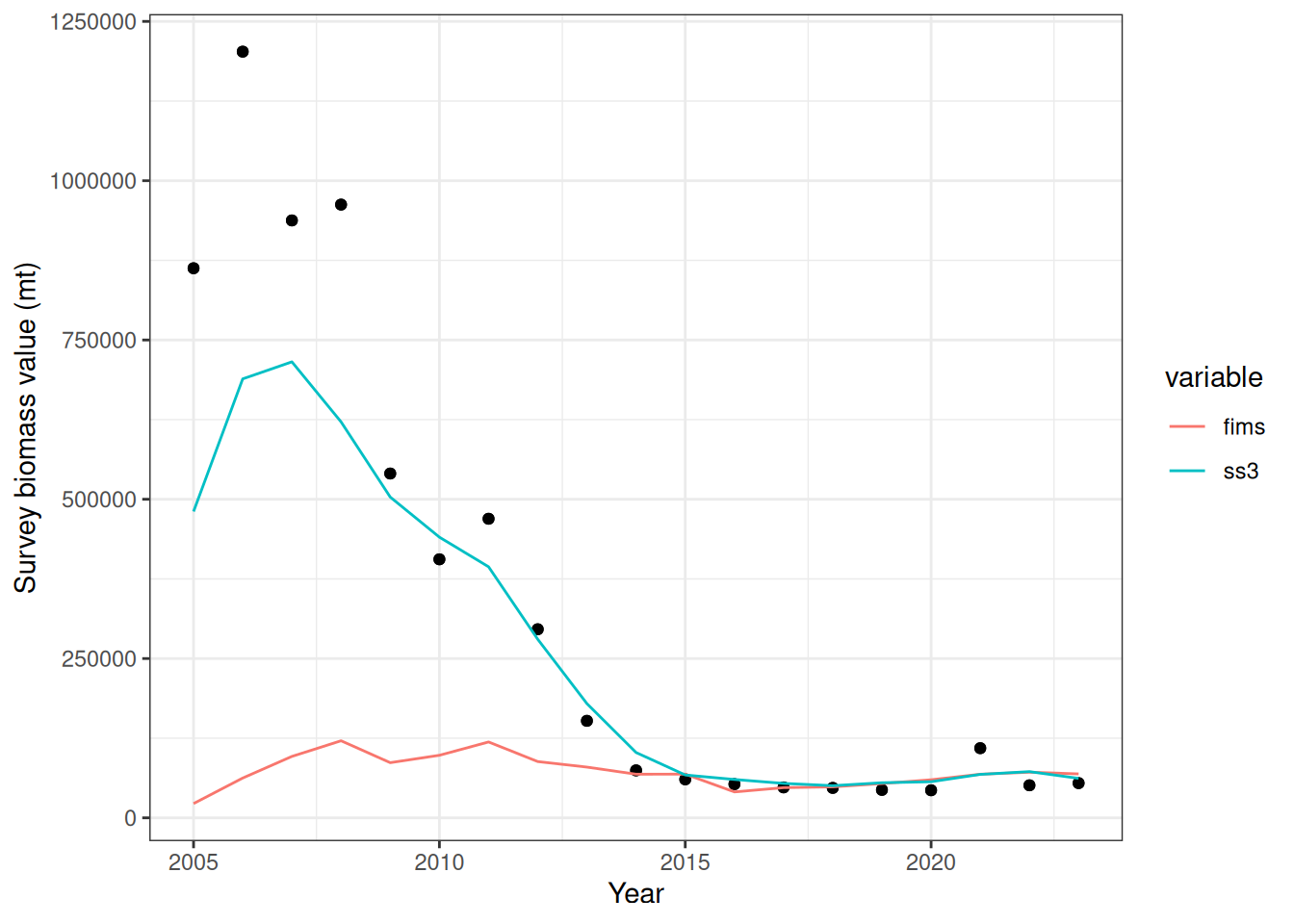
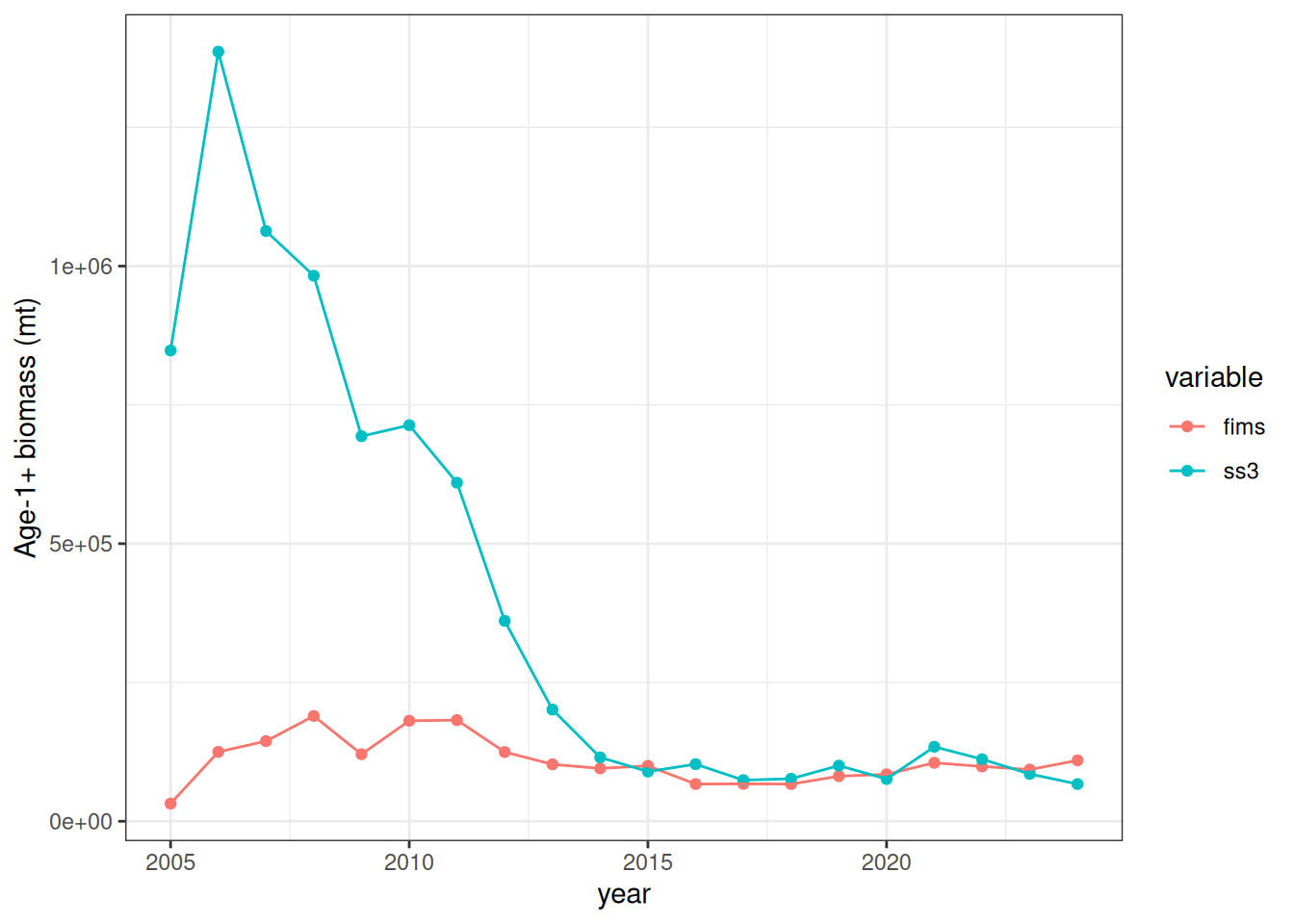
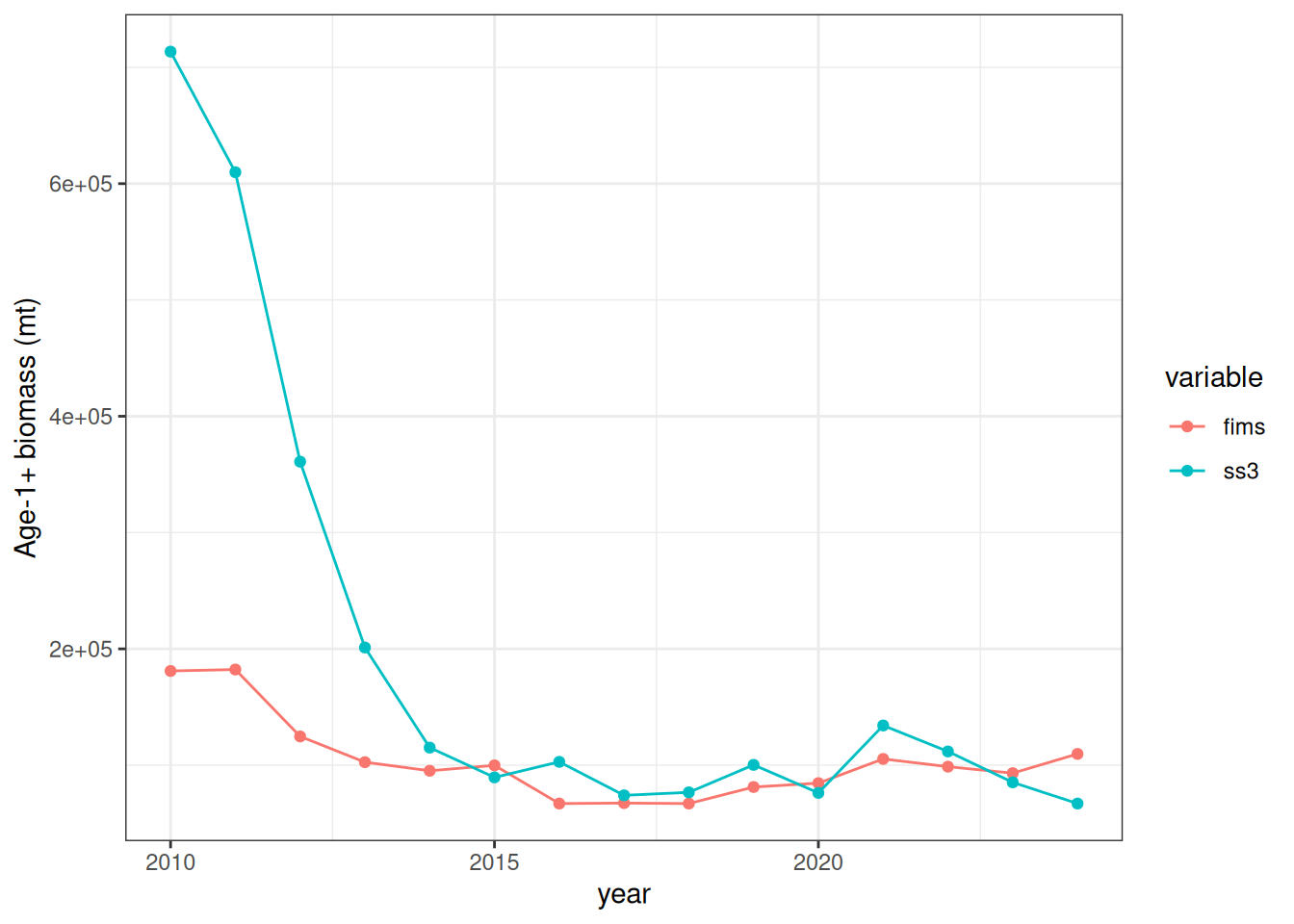
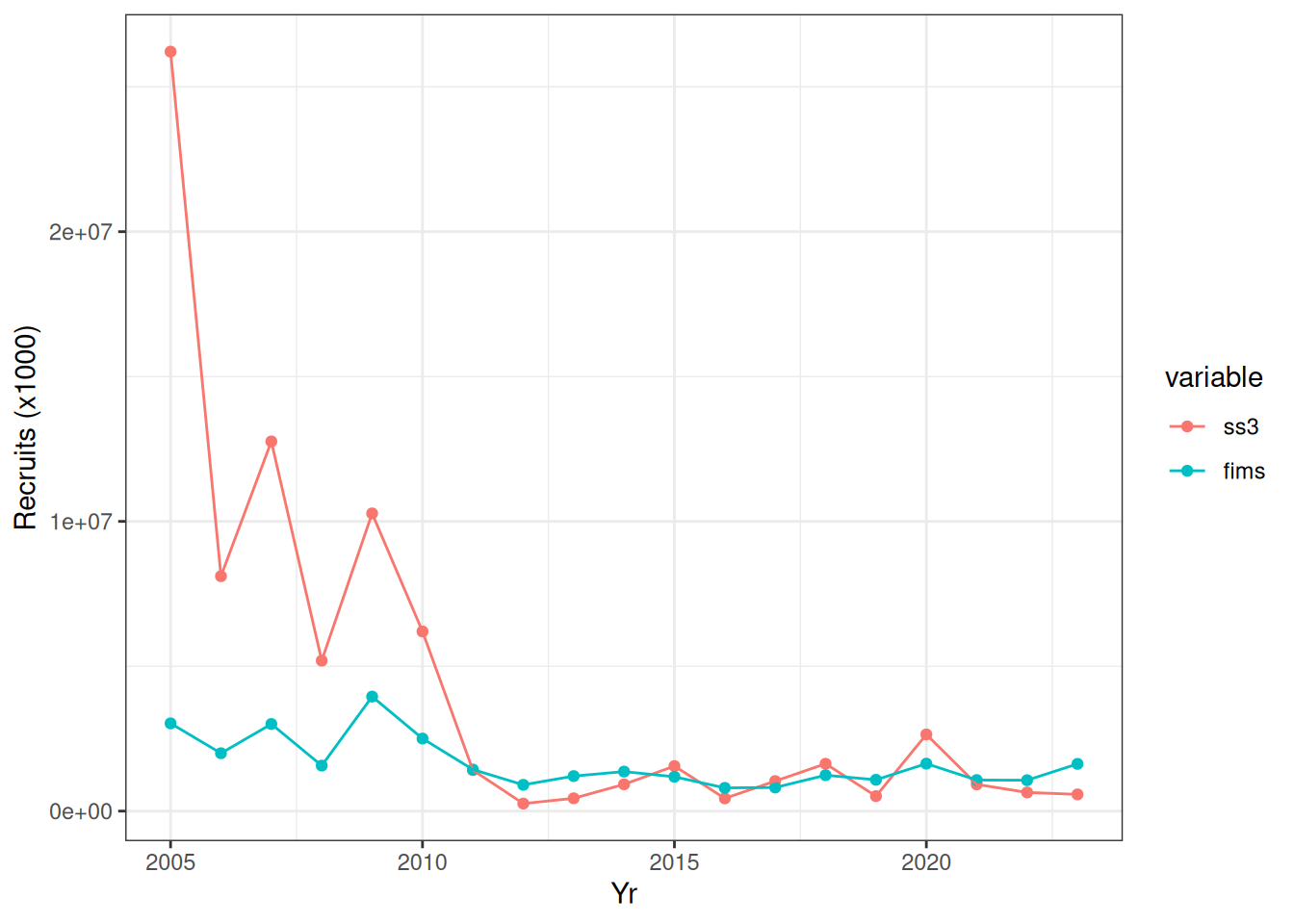
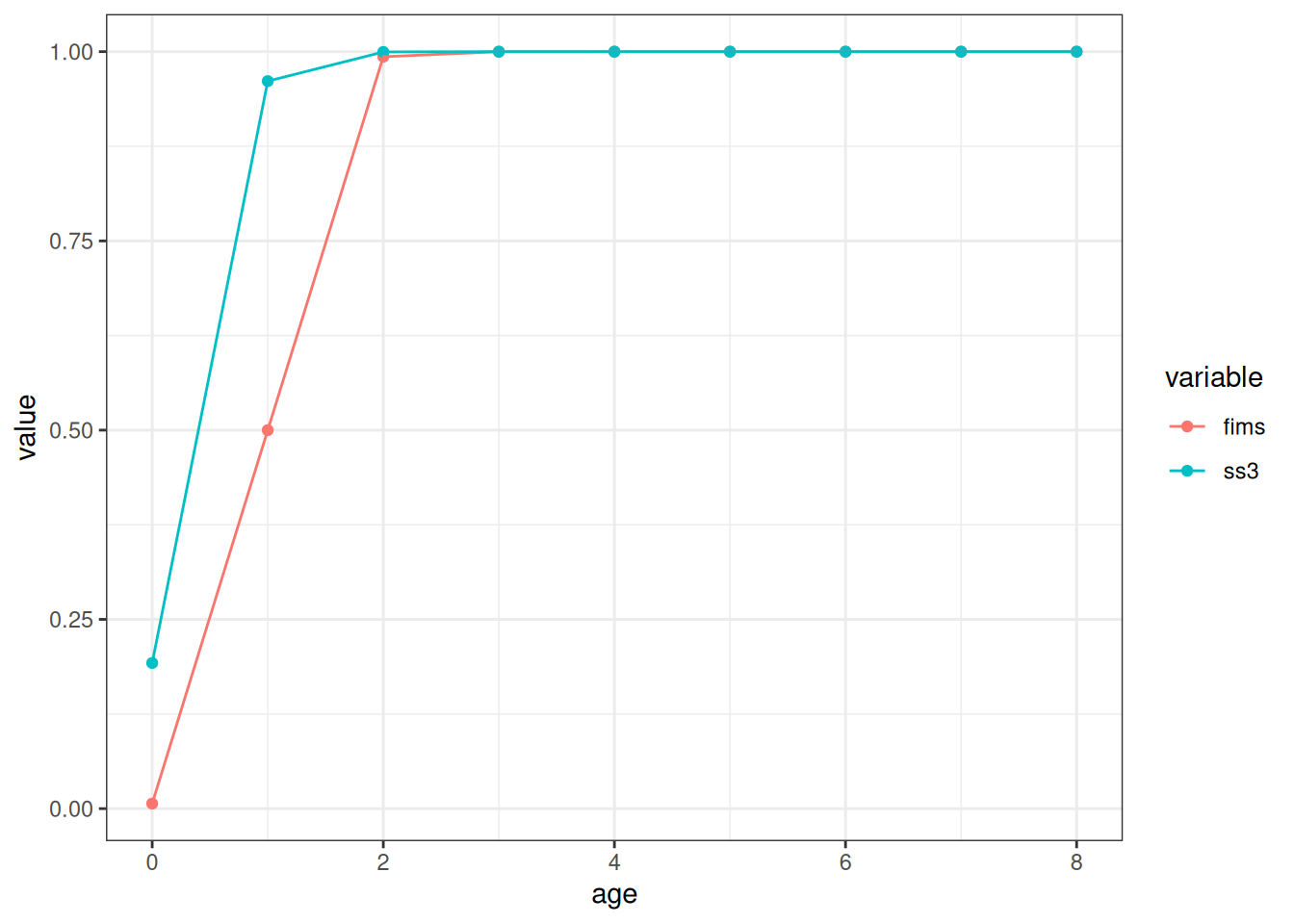
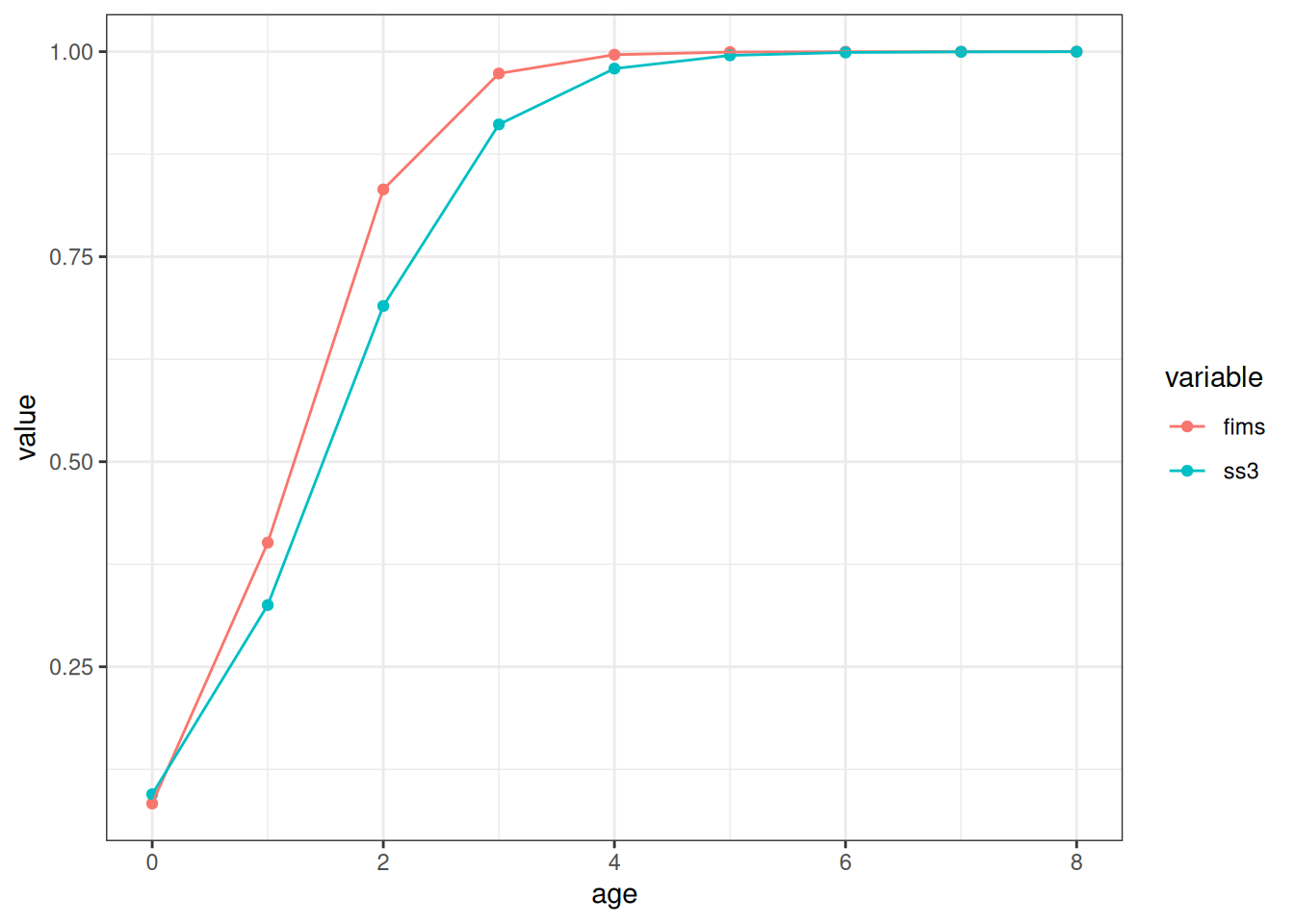
FIMS::clear()
#--------------------------------------------------------
#Logistic function for later use
logistic <- function(x, slope, inflection_point){
out <- 1 / (1 + exp(-1 * slope * (x - inflection_point)))
out <- data.frame(x = x, value = out)
return(out)
}
#--------------------------------------------------------
#Manually enter data
# setwd("C://Users//peter.kuriyama//SynologyDrive/Research//noaa//FIMS")
#-----Catch
catch <- data.frame(year = 2005:2023, catch = c(29188.50, 53107.00, 69929.40,
56317.80, 33546.40, 17466.40, 39383.10, 2585.38, 5705.77, 2558.63, 7.18, 428.26,
347.11, 514.20, 619.04, 653.15, 285.89, 508.02, 152.31))
# ggplot(catch, aes(x = year, y = catch)) + geom_point() +
# geom_line() + scale_y_continuous(label = comma)
fimscatch <- tibble::tibble(type = "landings", name = "fleet1",
age = NA, timing = catch$year, value = catch$catch,
unit = "mt", uncertainty = 0.05)
#-----CPUE
cpue <- data.frame(year = 2005:2023, obs = c(649619.0, 899635.0, 956354.0, 863281.0, 652029.0,
504970.0, 395783.0, 293980.0, 182417.0, 89260.1,
46403.0, 40704.0, 44592.1, 48789.1, 53551.8,
59765.8, 68451.7, 71612.5, 68957.9))
# ggplot(cpue, aes(x = year, y = obs)) + geom_point() + geom_line() +
# scale_y_continuous(label = comma)
fimsindex <- tibble::tibble(type = "index", name = "survey1",
age = NA, timing = cpue$year,
value = cpue$obs, unit = "mt", uncertainty = .3)
fimsindex$unit <- ""
#-----Age compositions
acomps <- utils::read.csv(file.path(data_directory, "sardine_acomps.csv")) |>
dplyr::mutate(value_prop = value / Nsamp) # convert age-comp data to proportions, to match fims-demo.Rmd
fimsage <- tibble::tibble(type = "age_comp", name = acomps$name,
age = acomps$age, timing = acomps$Yr,
value = acomps$value_prop, unit = "proportion", uncertainty = acomps$Nsamp)
#fimsage$uncertainty <- 50 Leave as empirical values
#-----Weight-at-age
# Q: What are the differences in how SS3 and FIMS process wtatage inputs/units?
# A: SS3 assumes WAA is expressed in kg, and then converts to mt for biomass calculations
# SS3 also expresses natage in terms of 1000s/fish
# FIMS assumes WAA is expressed in mt, but expresses natage in fish
# WAA input values are supplied to SS3 in kg and FIMS in mt
# Model now correctly processes inputs and provides comparable NAA, WAA, and biomass outputs to SS3
wtatage <- r4ss::SS_readwtatage(file.path(data_directory, "sardine_wtatage.ss_new")) |>
dplyr::filter(fleet %in% c(1, 2)) |>
dplyr::mutate(fleet = ifelse(fleet == 1, "fleet1", "survey1")) |>
tidyr::pivot_longer(cols = `0`:`10`, names_to = "age", values_to = "value") |>
dplyr::filter(year != 2024, !(age %in% c("9", "10"))) |> # Trim ages 9 and 10 to match age-comps
dplyr::mutate(value = value / 1000) # WAA converted from kg to mt
fimswaa <- tibble::tibble(
type = "weight-at-age",
name = wtatage$fleet,
age = wtatage$age,
timing = wtatage$year,
value = wtatage$value,
unit = "mt",
uncertainty = NA
)
#Combine everything, format
data_4_model <- rbind(fimscatch, fimsindex, fimsage, fimswaa)
data_4_model$age <- as.integer(data_4_model$age)
data_4_model$value <- as.numeric(data_4_model$value)
# Convert to FIMSFrame
data_4_model <- FIMS::FIMSFrame(data_4_model)
n_years <- FIMS::get_n_years(data_4_model)
years <- FIMS::get_start_year(data_4_model):FIMS::get_end_year(data_4_model)
n_ages <- FIMS::get_n_ages(data_4_model)
ages <- FIMS::get_ages(data_4_model)
rzero <- 17 #14.2 is log(R0) in sardine simplified model
M_value <- 0.8 #.8 worked pretty well
init_naa <- exp(rzero) * exp(-(ages - 1) * M_value)
init_naa[n_ages] <- init_naa[n_ages] / M_value # sum of infinite series
# Create default recruitment, growth, and maturity parameters
parameters <- FIMS::create_default_configurations(data = data_4_model) |>
FIMS::create_default_parameters(data = data_4_model) |>
tidyr::unnest(data) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Selectivity",
label = rep(c("inflection_point", "slope"), 2),
value = c(1, 5, 1.2, 2),
estimation_type = "constant",
fleet_name = rep(c("fleet1", "survey1"), each = 2)
),
by = c("module_name", "label", "fleet_name")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Recruitment",
label = "logit_steep",
value = FIMS::logit(0.2, 1.0, 0.6)
),
by = c("module_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Recruitment",
label = c("log_rzero", "log_sd"),
value = c(rzero, log(1.2)),
),
by = c("module_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Recruitment",
label = "log_devs",
value = log(1),
),
by = c("module_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Maturity",
label = c("inflection_point", "slope"),
value = c(1.2, 1.5) # 1.5 is arbitrary guess
),
by = c("module_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Fleet",
fleet_name = "survey1",
label = "log_q",
value = 0,
estimation_type = "constant"
),
by = c("module_name", "fleet_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Fleet",
fleet_name = "fleet1",
label = "log_Fmort",
value = log(0.2)
),
by = c("module_name", "fleet_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Population",
label = c("log_M"),
value = log(M_value)
),
by = c("module_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Population",
label = c("log_init_naa"),
age = ages,
value = log(init_naa),
estimation_type = "fixed_effects"
),
by = c("module_name", "age", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Data",
fleet_name = "fleet1",
label = "log_sd",
value = log(sqrt(log(0.01^2 + 1))),
estimation_type = "fixed_effects"
),
by = c("module_name", "fleet_name", "label")
) |>
dplyr::rows_update(
tibble::tibble(
module_name = "Data",
fleet_name = "survey1",
label = "log_sd",
value = log(sqrt(log(0.1^2 + 1))),
estimation_type = "fixed_effects"
),
by = c("module_name", "fleet_name", "label")
)